세상의 모든 개미분들에게 유의미한 통찰력을 제시할 수 있는 서비스를 구현하기 위한 과정입니다.
대주주Go
1. 제목 그대로 주식 투자를 위한 가이드 라인 제시가 목적 2. AI를 활용해 주가 차트를 분석 3. 우선 각가의 주가 차트를 분석해 다음 연도의 주가를 예측하는 식으로 반복학습 4. 이를 기준으로
thebeworld.tistory.com
이 과정을 통해 만들고자 하는 결과물들은 다음과 같습니다.
1. 기존의 육안이나 단순 지표로 만들어진 것 이상의, AI를 통해 추측한 종가 추세선
(One-step 단순 예측과 Multi-Step의 좀 더 높은 수준의 예측)
2. 위의 추세선을 통해 해당 주식의 정기적, 주기적 변동을 파악해 안정적인 투자
3. AI가 예측하지 못하는 변동을 비주기적 변동으로 정의하고, 해당 변동에는 어떠한 요소가 반영되었는지 비정기적 이벤트 뉴스와 SNS를 통해 크롤링(수집)
4. 이렇게 수집한 데이터를 통해 해당 주식이 어떤 요인에 의해 비주기적인 변동을 경험하는지, 때문에 미래에 어떤 키워드나 사건을 조심해야하고, 기대해야하는지를 도출
5. 궁극적으로 이러한 것들을 통해 어느 시기와 주가 구간에서 매수하고, 매도해야하는지를 긴박한 시류의 흐름 속에서이리저리 떠밀리듯이 주식거래를 하는 것이 아닌 미리 준비할 수 있도록 하는 것이 목적.
즉, 이 프로젝트 과정에서 기본적인 가정은 다음과 같습니다.
1. 주식은 주기적인 변동과 비주기적인 변동을 통해 주가가 변화한다.
2. 주기적인 변동은 신상품의 출시, 상품 및 서비스의 특징을 반영한 계절적 변동, 특정 시기에 열리는 컨퍼런스나 이벤트의 반복 등을 의미하며, 수개월에서 수년간의 전체적인 변동은 이에 따라 이루어진다.
3. 비주기적인 변동은 CEO의 교체, 경쟁사의 압도적 성장, 기타 비즈니스적 실수나 실패 등으로 인한 변동을 의미하며, 이러한 비주기적인 변동이 더욱 큰 변동폭을 가진다.
STEP 01. 데이터 수집
주가의 정기적 변동을 적어도 80% 이상 예측할 수 있고, 이러한 예측값에 대한 로스를 최소화하는 모델링을 만드는 것이 첫 번째입니다. 우선 기본적인 주가 데이터를 수집해보겠습니다.

Yahoo Finance를 통해 받아온 2013년부터 2018년까지 스타벅스의 6년치 주가 정보입니다. 제일 왼쪽부터 해당 주식의 수집한 주식 정보의 날짜, 시작가, 고가, 저가, 종가, 수정종가, 거래량입니다.
작업 환경은 GOOGLE COLAB입니다.
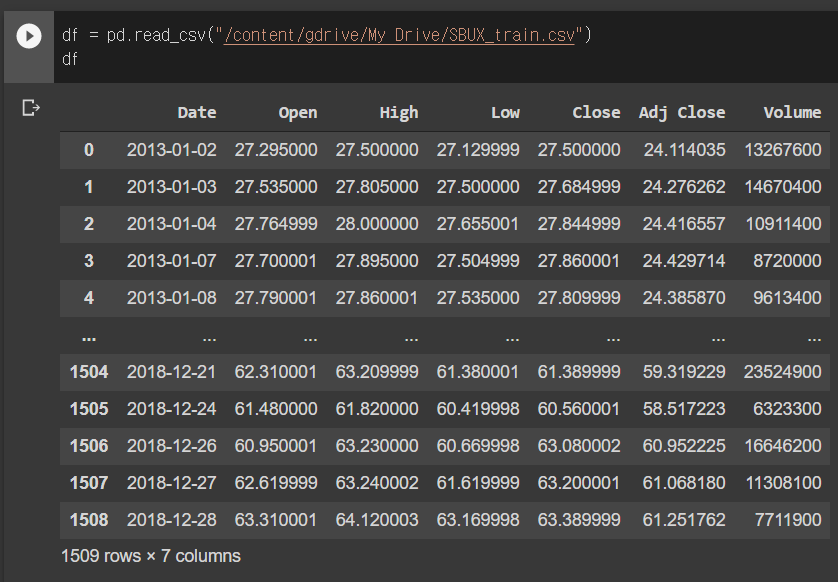
우선 데이터를 불러오고 제대로 불러왔는지 확인해보겠습니다. 저같은 경우엔 구글 드라이브에 올리고, 그 드라이브를 COLAB에서 바로 마운트하는 식으로 데이터를 가져왔습니다.
위 데이터는 약 20년치 네이버의 주식 정보입니다. 이를 시각적으로 한 번 파악해보겠습니다.
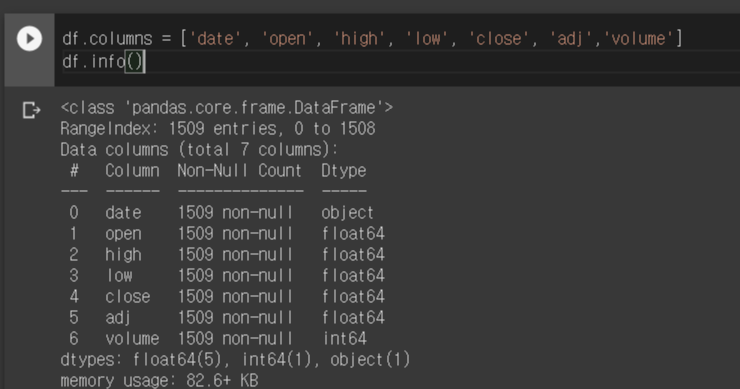
먼저 데이터 분석하는 과정에서 불편함을 없애기 위해 데이터의 변수명을 직관적으로 변경해주었습니다.

2013년부터 2018년까지 6년간 일별 시작가와 종가를 그래프로 그린 모습입니다. 푸른색 선이 종가 데이터로 삐쭉 튀어나와있는 구간이 시작가와의 격차가 많이 발생한 날, 혹은 구간이라고 볼 수 있겠습니다.
STEP 02. 데이터 분석
사실 가장 쉬운 예측과 분석은 주가를 그대로 집어넣어 하는 분석입니다.
이는 무척이나 직관적인 대신, 예측율이 떨어집니다. 하지만 그럼에도 많은 주식 투자자들은 주가 그래프를 보며 고저를 파악하곤 하는데, 이러한 단순한 예측은 그러한 부분을 보완해줄 수 있습니다.
한 번 해보겠습니다.
[단순 종가 예측 - One Step Analysis]
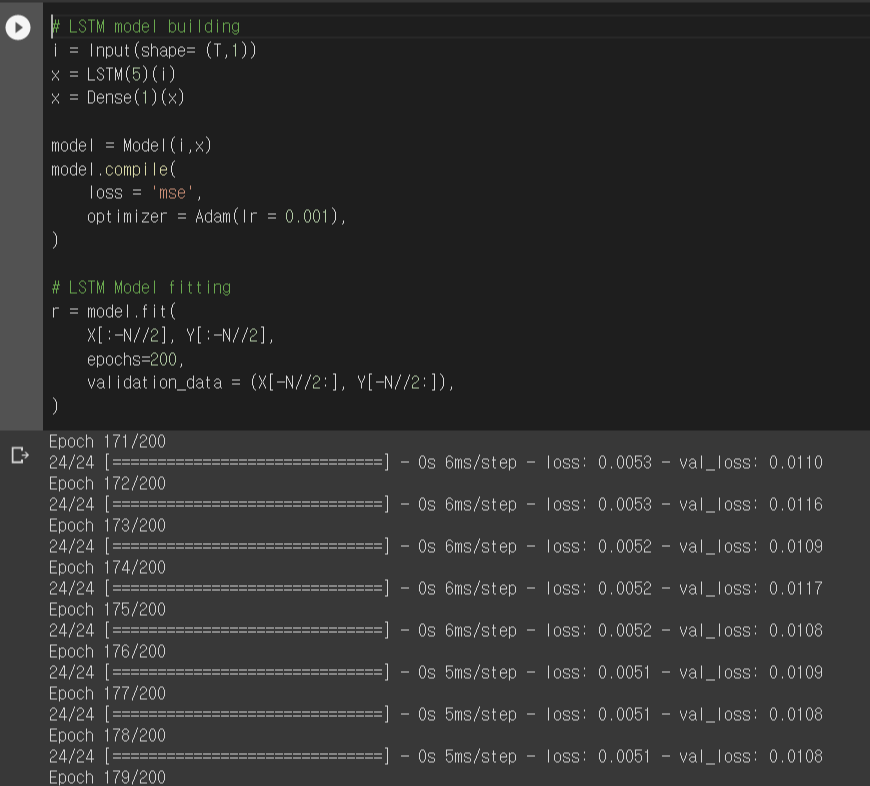
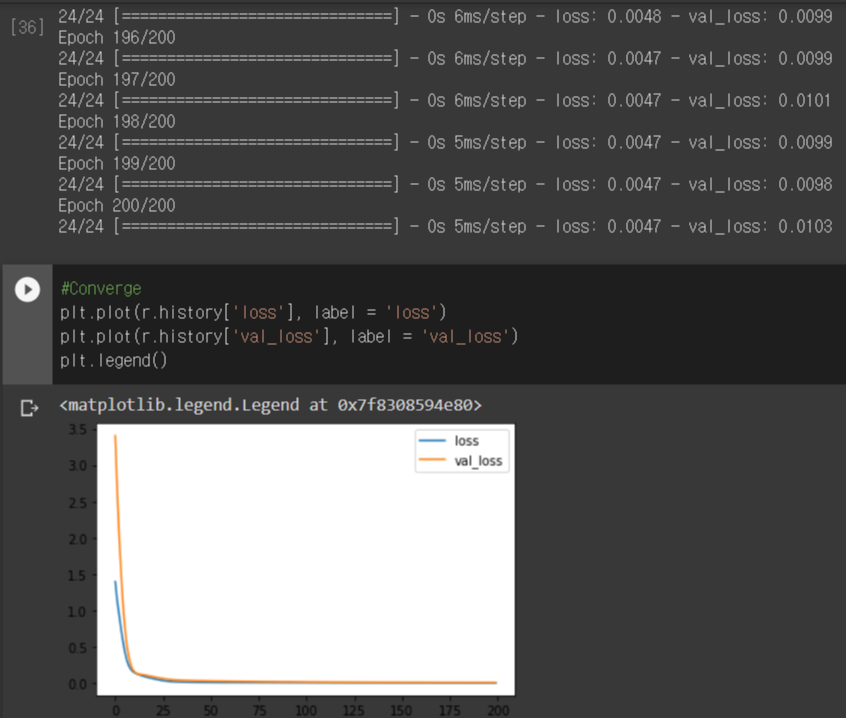
위에서 보이는 바와 같이 모델 학습이 완료되었습니다. 데이터 학습에 대한 로스와 예측에 대한 로스가 동시에 줄어들며 결과적으로 낮은 수준에서 수렴하는 것을 확인할 수 있습니다.
이는 원활한 학습을 위해 기간을 2013년부터 2018년을 넣은 것이기도 한데요, 이는 경제 대공황이나 올해의 코로나와 같이 극심한 경제난과 그로 인한 변동성을 유발시키는 데이터를 제외했기 때문에 데이터를 기반으로 한 예측에 유리합니다. 반대로 위와 같은 혼란 시기의 데이터는 추후 다시 분석해보도록 하고, 우선은 안정기의 데이터 분석과 예측을 이어가보겠습니다.
이렇게 학습한 모델을 기반으로 주식 그래프를 그려보겠습니다. 그리는 방식은 이전 10일치의 종가를 기반으로 자체적으로 학습한 알고리즘에 따라 그 다음날의 종가를 예측하는 것을 반복하는 것입니다.

노란 선이 알고리즘이 연속해서 찍은 종가점들을 이은 그래프이고, 파란선이 실제 데이터를 반영한 그래프입니다. 변동성이 일정 수준 이상인 것에 대한 부분은 예측력이 떨어지는 모습을 보이나 전체적인 경향 자체는 잘 반영하고 있음을 확인할 수 있습니다.

같은 그래프를 예측선만 표시한 뒤 실제값과의 차이를 색칠해보았습니다. 위에 보이는 붉은 구간이 실제값보다 높게 예측한 구간이고, 녹색 구간이 실제값보다 낮게 예측한 구간입니다.
이번엔 LSTM을 변형한 프레임워크인 GRU (Gated Recurrent Units)을 사용해 분석해보겠습니다.

훈련 데이터에 대한 로스값은 LSTM으로 했던 0.0047 수준에서 0.0035 수준으로, 예측 데이터에 대한 로스값은 0.01 수준에서 0.0078 수준으로 향상되었습니다.
LSTM과 마찬가지로 그래프를 그려보겠습니다.


그래프를 그려봤을 때 LSTM과의 유의미한 차이는 바로 실제치보다 높게 예측한 구간이 대부분 사라졌다는 것입니다. 이는 실제 기업가치를 과대평가하는 구간이 사라졌다는 것을 의미하며, 막연히 과소평가가 과대평가보다 낫다고 할 수는 없지만 직관적으로 예측 오차가 줄어들었다는 점과 이로 인해 잘못된 투자를 하는 것을 방지할 수 있다는 부분에서는 꽤나 매력적인 지표라 할 수 있겠습니다.