지난 번에 이은 두 번째 과정입니다.
[대주주 go] 1편 : 데이터 가져와서 분석하기
세상의 모든 개미분들에게 유의미한 통찰력을 제시할 수 있는 서비스를 구현하기 위한 과정입니다. 더보기 2020/10/22 - [아이디어/개발 아이디어] - 대주주Go 대주주Go 1. 제목 그대로 주식 투자를
thebeworld.tistory.com
저번 시간까지 종가 데이터만을 활용해 그 다음 날의 종가를 예측하는 것을 이어나가는 방식으로 그래프를 그려보았는데요, 사실 그 방법은 본래 많은 투자자들이 주먹구구식으로 하던 등락 그래프를 조금 더 예쁘게 그려줄뿐 그 이상의 신뢰도를 가지긴 어렵습니다.
정확히 말하면 주식의 가격은 그 회사의 정기적인 이벤트와 비정기적인 이벤트, 그 회사의 재무적인 상황, 동향, 사람들의 기대와 그것을 예측한 여러 투자자들의 선점 등이 복잡하게 어우러진 결과이기 때문에 고작 종가 하나로 그 모든 것을 반영해서 예측하기란 논리적인 오류가 있을 수밖에 없습니다.
그렇기에 이번 시간에는 보다 명확하게 예측이 가능하도록 분석 변수의 개수를 늘려주고, 예측하는 값 또한 구체적으로 얼마다~ 하는 식으로 하기보다 오를 것인지 여부만을 맞춰보는 식으로 진행해보겠습니다.
STEP 01. 개요
본 프로젝트는 크게 3가지 상황을 다룰 것입니다.
첫 번째는 우리가 살고 있는 현실이라고 할 수 있습니다. 2001년부터 2020년 현재까지의 스타벅스 데이터를 가져와 분석해볼 것입니다. 이 과정에서 단순히 종가를 예측하는 것이 아닌 실질적인 수익성을 따지기 위해 지금 주식을 샀을 때, 수익을 얻을 수 있는지 여부를 학습하고 예측해보겠습니다.
두 번째는 호황시기의 현실입니다. 2010년부터 2019년까지의 10년의 기간으로 대부분의 미국 우량주의 경우 우상향하는 곡선을 그리고 있습니다. 때문에 실질적인 수익율이라고 할 수 있는 3% 이상의 이익을 맞출 수 있냐 없냐를 기준으로 학습하고 예측해보겠습니다.
마지막으로 세 번째는 불황시기의 현실입니다. 2006년부터 2009년, 그리고 2020년의 데이터가 여기에 속합니다. 총 5개 년도의 데이터로 데이터의 양 자체가 그리 많지 않기 때문에 학습 정도나 신뢰성이 그리 높지는 않을 것으로 예상되나 만약 경제위기가 어느정도 극복되고 회복되었던 2009년의 데이터를 학습한 머신이 만약 코로나가 회복된다면 어떤 식으로 미래를 예상할지를 예측할 수 있을 것으로 기대할 수 있습니다. 목표 예측 정확도 수준은 70%입니다.
바로 시작해보겠습니다.
STEP 02. 2001년부터 2020년
우선 데이터를 불러오겠습니다.

불러온 데이터에는 지난 번과 동일하게 수집 날짜, 시작가, 고가, 저가, 종가, 수정종가, 거래량의 7개 변수를 기준으로 나열되어 있습니다. 총 4991개의 데이터입니다.
데이터 분석을 하기에 앞서 가공이 쉽도록 열 이름을 정리해주겠습니다.
앞글자가 대문자인 친구들을 소문자로, 뒤에 CLOSE가 붙어있던 수정종가를 ADJ로만 저장했습니다.
지난 번과는 다르게 이번에는 위의 데이터에 더해 한 가지 변수를 더 추가해주겠습니다.
쉬프트 함수를 사용해 전날의 수정종가를 불러와 오늘의 수정종가와 비교해 수익율을 산출해보았습니다. 이러한 값으로 데이터 학습을 시켜본 결과 단순히 종가만을 변수로 분석했을 때보다는 높지만 그래도 50%에 수렴하는 통계적으로 의미가 없는 수치가 나왔습니다.
다른 변수를 추가해보겠습니다.
기본적으로 날마다 주식가격의 변동성이 높은 수준이다보니 정확히 예측하려면 하루 단위의 정밀한 분석이 이루어져야 하는데, 현실적인 데이터의 양이나 분석툴의 한계로 인해 이러한 분석은 어렵습니다. 따라서 실제 주식 분석에도 사용되는 5일 간의 이동평균값을 통해 변동성을 줄이고, 희석하는 과정을 진행했습니다.
이렇게 만들어낸 값으로, 미래의 수익율과 비교해보는 열을 추가했습니다.
1d가 하루 뒤에 얻을 수익율이고, 1m가 한 달, 2m가 두 달...이런 식으로 1년 뒤까지를 분석해보는 과정입니다.
본격적인 분석 전에 5일 평균 수정종가를 만들고, 이를 미래 데이터와 비교하는 과정에서 생긴 열 안의 NaN을 모두 없애주겠습니다. 만약 이를 없애지 않을 경우 loss값과 val_loss이 모두 NaN으로 나오고 지나치게 높은 수준의 정확도를 보이는 에러가 발생하게 됩니다.
하루 뒤의 수익률이 0 이상인지를 학습하고 예측한 결과입니다.
학습이 반복될수록 정확도가 수렴하고 있지만, 데이터 학습 정확도가 1에 수렴하는 동시에 val_loss가 발산하는 모습을 보여주고 있습니다. 전형적인 과적합 결과로 볼 수 있는데, 예측의 정확도 자체는 60%가 넘어도 오히려 어느 정도의 예측 노이즈가 발생했을 때 로스가 더 낮은 수준입니다.
한 달 뒤의 수익율이 0 이상일지를 학습하고 예측한 결과입니다.
epoch가 늘어남에 따라(학습이 진행됨에 따라) 예측 정확도는 별다른 상승을 보이지 않는 반면 로스는 커지고, 동시에 학습 데이터에 대한 정확도만 늘어나는 전형적인 과적합 상황입니다. 실질적으로 이런 식의 분석결과가 나왔을 경우, 이를 통해 인사이트 등을 얻는 것을 불가능에 가깝기에 변수를 더 추가하거나 다른 모델로 학습시키는 등의 과정이 필요합니다.
일단은 계속 진행해보겠습니다.
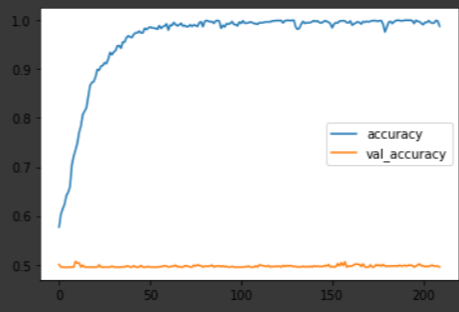
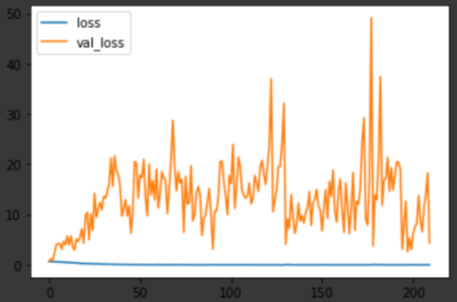
두 달 뒤의 수익율을 학습하고 예측한 결과입니다.
비록 학습이 완료될 때까지 예측 로스가 수렴하는 형태를 보이진 못하고 있으나 더이상의 성능 향상이 없어 사전에 입력해둔 옵션에 따라 정지한 상황입니다. 로스값이 안정되는 형태를 보이곤 있으나 여전히 과적합되는 경향을 보여주고 있습니다.
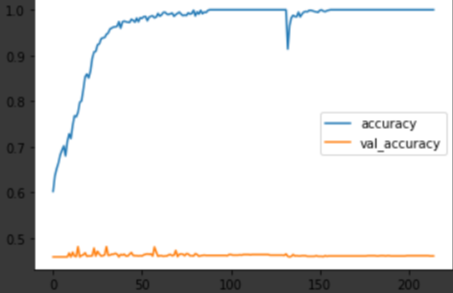
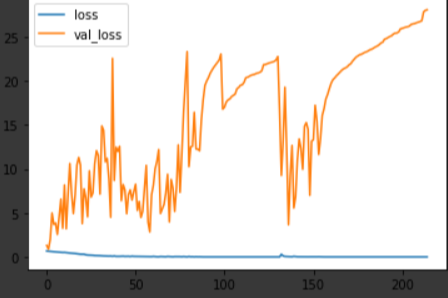
세 달 뒤의 수익율을 학습하고 예측한 결과입니다.
여전히 예측율은 50%를 밑돌고 있으며, 학습 결과는 과적합 상황을 보이고 있습니다.
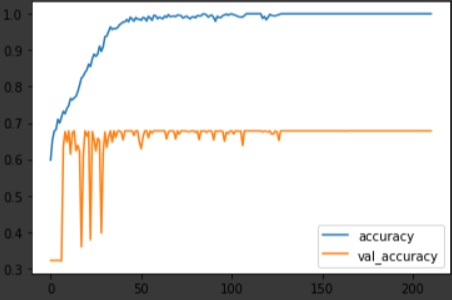
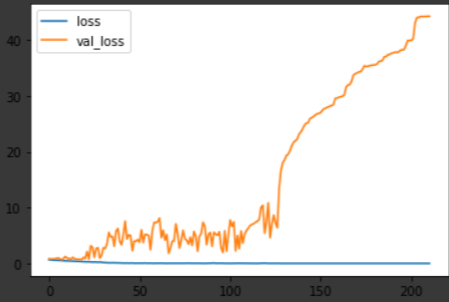
여섯 달 뒤의 수익율을 학습하고 예측한 결과입니다.
그래프의 모습만 보면 그리 다르지 않은 결과라 여겨질 수도 있지만 한 가지 큰 변화가 있었습니다. 바로 미래에 대한 예측 정확도가 67% 정도로 상승한 상태로 수렴한다는 것인데요, 비록 로스가 수렴하지 않고 꽤나 큰 값으로 변동하다 발산하기 때문에 이 자체만으로 신뢰할만한 무언가를 얻을 수 있지는 않습니다. 그저 3개월까지의 데이터 학습과 예측은 정확도와 오차가 모두 컸던 반면, 6개월 뒤의 미래 예측에서는 오차는 여전하지만 보다 정확한 예측이 가능했다 정도만 확인하고 넘어가겠습니다.
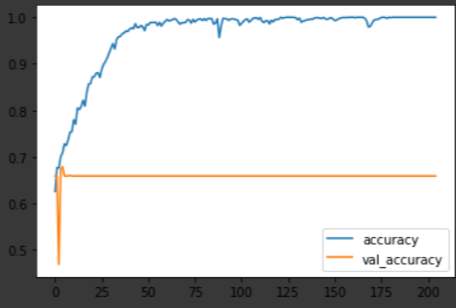
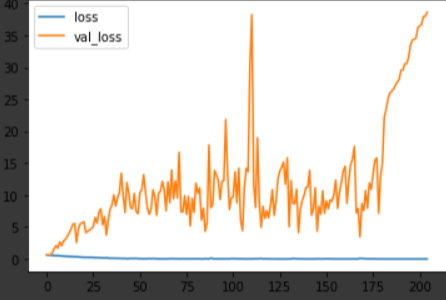
일 년 뒤의 수익율 학습과 예측 결과입니다.
여기서도 여전히 로스값이 안정되지 못하는 모습을 보이는데요, 반면 수익율에서는 또 다른 변화가 생겼습니다. 바로 예측율이 빠르게 수렴하며 학습한 것인데요. 오히려 가까운 기간을 예측하는 것보다 먼 미래를 예측하는 것이 더욱 간단한 프로세스를 기반으로 예측할 수 있으며, 그 정확도도 오히려 높다라는 결과를 얻을 수 있었습니다.
수익율을 딥러닝 학습 시킴으로써 주식 투자에 도움이 될 수 있는 알고리즘을 만들고자 했는데, 의도치 않게 장기투자가 단기투자에 비해 오차 수준은 비슷할지라도 정확도는 훨씬 높다는 것을 증명해버렸습니다. 그 외에는 이 과정에서도 꽤나 작지 않은 수준의 로스가 반복되고 있어 본래 의도했던 비즈니스적인 임팩트를 발생시키는 어려워보입니다.
한 눈에 보는 미래 예측 결과입니다.
하루 단위의 예측이 변동성이 가장 높은 수준으로 반복되어 이어지다가 3위 수준으로 수렴했고, 6개월 뒤 예측이 2번째 수준의 변동성을 기반으로 가장 높은 예측율을, 1년 뒤 예측이 1번째 수준의 변동성을 기반으로 두 번째로 높은 예측율을 기록했습니다.
STEP 03. 변수 추가
여기까지 단순 분석을 해본 결과 좀 더 먼 기간의 예측 정확도가 단기간 예측 정확도보다 높다는 것 이외에는 인사이트를 얻을 수 없었는데요, 보다 정확한 분석을 위해 변수 간의 상관관계를 체크해보겠습니다.
변수 간의 상관관계를 seaborn이라는 라이브러리를 통해 시각적으로 표시했습니다.
여기서 확인할 수 있었던 것은 미래 수익율 지표들이 다른 주식의 기본변수들에 대한 상관계수는 낮은 반면, 다른 예측값들에 대한 상관계수가 높다는 점이었습니다. 예를 들어 1년 뒤 수익율 값과 6개월 뒤 수익율 값은 0.78 의 높은 상관관계를 지니고 있고, 6개월 뒤 수익율 값은 3개월 뒤 수익율값과 0.77이라는 높은 수익율 값을 보이고 있는 것입니다.
이러한 상관계수를 반영해서 과연 지금 6개월 뒤의 예측했던 이전의 과정보다 6개월 전에 현재 데이터를 반영해 1년 뒤를 예측하는 과정이 더 예측율이 높은지 비교해보겠습니다.
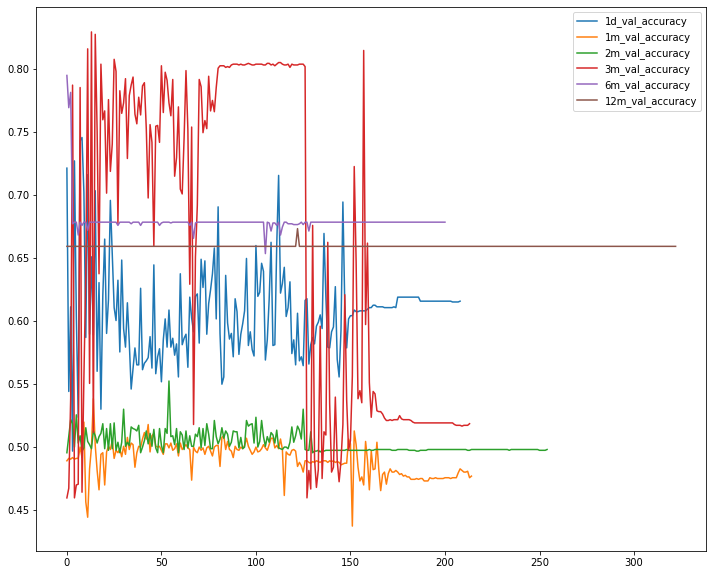
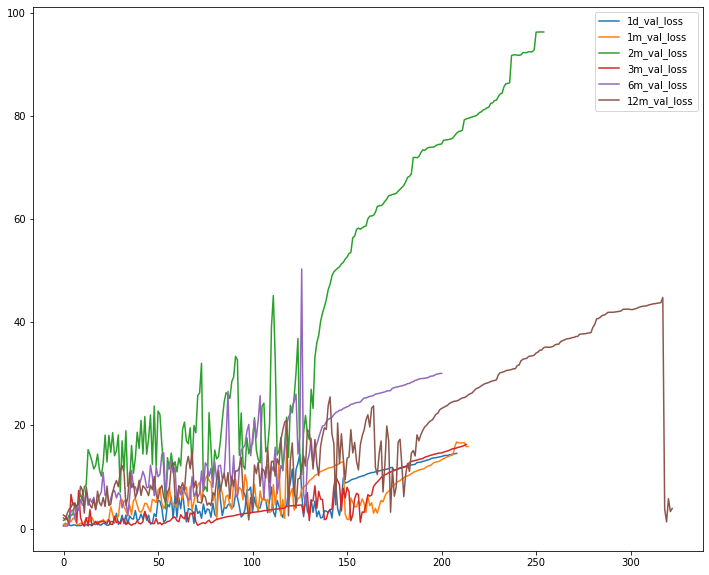
전반적으로 예측력이 약간 상승했습니다. 다만 이 과정에서 과적합을 피할 수는 없었는데요, 본래 사회적 현상의 하나라고 봐도 되는 주식이기에 오차율의 변동없는 완벽한 학습은 현실적으로 불가능합니다. 다만 딥러닝 과정에서 억지로 이를 학습시키다보니 오차율을 높이더라도 수렴하려고 하는 것입니다.
이러한 점을 고려해, 이번에는 기간별로 수익율을 정한 뒤에 이러한 알고리즘이 해당 수익율을 달성할 확률로 분류하여 구분짓는 softmax activation을 사용해 각 기간별 예측 정확도를 일정 수준으로 안정화시키고 동시에 로스값을 줄여보는 방향으로 가보겠습니다.
softmax activation은 해당 프로세스에서 여러 과정으로 분류해주는 기능을 하기 때문에 분류 작업의 마지막에 쓰이거나 그 직전에 사용되어 정확도와 로스를 시각화 관점에서 안정화시킬 수 있습니다. 만약 softmax를 마지막에 쓰면 맞출 확률과 맞추지 못할 확률이 양극단으로 나뉘어 파동을 그리게 됩니다.
이러한 이유로 딥러닝의 마지막 과정에서 softmax로 여러 경우의 수를 분류해주었고, 그것을 다시 relu로 받아 결과를 도출했습니다. 위의 그래프에서 보면 6개월과 1년 뒤 월평균 3% 이상의 수익율 예측 정확도가 제일 높습니다(두 선이 겹쳐있습니다). 그 뒤로는 3개월, 2개월, 1개월, 하루 순으로 이전에 보았던 것처럼 기술적 분석을 통해 주가 예측을 할 경우 월평균 같은 수준의 수익을 기대하더라도 오히려 먼 미래를 예측하는 것이 정확도가 높습니다.
반면 아래의 로스값은 12개월과 6개월 뒤의 예측이 가장 낮은 수준이며, 다시 역순으로 3개월, 2개월, 1개월, 하루순으로 로스값이 높습니다. 이러한 이유로 인해 위에서 판단한 장기 투자의 필요성이 증가했습니다.
다음 번에는 스타벅스 주식을 호황기와 불황기로 나누어 분석해보고, 해당 알고리즘은 해외 다른 주식과 국내 주식에도 적용해보겠습니다.
여기까지의 프로젝트를 통해 얻은 인사이트는 다음과 같습니다.
INSIGHT 01. 장기투자(6개월 이상)가 단기투자(3개월 이하)에 비해 수익율 예측 정확도가 높으며, 그에 따른 오차율도 적다.
다만 이러한 분석은 주식이 선형성을 유지하는, 즉 계속영업이 가능하다는 가정하에 이루어진다는 점을 고려하셔야 합니다.